Upload Attempt Failed Time Out Reached for Upload Attempt
Beneath are common host and backup chore error messages you may encounter and what they mean.
This article is organized byAlarm Type:
- Backup Agent Task State Errors
- Job Session State Errors
- Chore Status Errors
- Figurer/VM Not Backed Up
- Miscellaneous
For Additional Errors Not Listed Below, Consult the Veeam Knowledge Base of operations and/or Forums:
- Veeam Noesis Base – https://world wide web.veeam.com/kb_search_results.html
- Veeam Community Forums – https://forums.veeam.com/
1. Backup Amanuensis Job Land Errors
Error: write: An existing connection was forcibly airtight by the remote host Failed to upload disk. Amanuensis failed to process method {DataTransfer.SyncDisk}.
What This Means
- The last backup task was unsuccessful because the remote host (motorcar backing upward) airtight the connexion to eSilo while the backup was running.
Possible Causes
- The auto was powered down during the fill-in. Upon shutdown, the active snapshot taken at the get-go of the backup is lost.
Troubleshooting Steps
- No user intervention is typically required. When the computer is powered dorsum on, a new snapshot will be taken at the adjacent scheduled backup fourth dimension, and a new backup job will begin. (Note: If the automobile is put to Sleep or Standby during a backup, it should resume when information technology wakes upward. It is but when the machine is completely powered down that this mistake happens).
Mistake: Task failed unexpectedly
What This Means
- The job was terminated suddenly, resulting in an incomplete backup and restore point.
Possible Causes
- Host rebooted during the fill-in, resulting in the loss of the active snapshot.
Troubleshooting Steps
- Check host'southward Consequence Viewer Windows Organization logs to see if there was a reboot.
- Rerun the backup job.
Unable to classify processing resources. Error: Chore session with id [String] does not exist
What This Means
- Host requested only was not assigned processing resources by eSilo deject connect. This happens because the maximum number of concurrent backup jobs was already reached.
Possible Causes
- eSilo limits the number of concurrent backup jobs from a single Company when their bandwidth is lower than recommended thresholds. This max limit ensures hosts queue their fill-in jobs sequentially (vs. all machines at in one case) and avoids network slowdowns for the customer.
- When the first few machines' fill-in jobs run long, they can cause subsequent hosts' jobs to fourth dimension out while waiting for their plough to backup.
Troubleshooting Steps
- Hosts should automatically retry backups at their next scheduled interval. No user intervention is typically required.
- If this is a persistent issue, or if your hosts are connecting from multiple locations (and thus there is little concern that multiple backups may saturate a site's connection), contact eSilo Support to request the concurrent job limit be increased for your Company.
Failed to start a backup chore. Failed to perform the operation. Invalid job configuration: Connection over network is blocked by network throttling rules
What This Means
- Backup job was unable to complete due to network restrictions.
Possible Causes
- The host is on a metered connection (ex: hot spot), or on a WiFi connectedness that has "Set as a metered connection" toggled on in the properties for the currently active WiFi connectedness. By default, eSilo Backup Jobs are gear up to "Disable backups over a metered connectedness".
- Temporary network congestion may besides cause this fault.
- Firewall rules that limit or severely restrict sure types of traffic.
Troubleshooting Steps
- To check if the current WiFi connectedness is flagged as "metered" by Windows, the user can navigate to the Backdrop of their WiFi Network, and scroll to "Metered Connection" to verify if this is toggled ON. The preferred setting is to turn this OFF. Alternatively, if y'all don't have remote access to the machine, uncheck the "Disable backups over metered connexion" setting in the backup job and rerun it.
-

- Wait until the side by side scheduled fill-in run to run into if the issue persists or was temporary.
- Contact the network or It ambassador for the site to investigate if there were contempo firewall dominion changes or upgrades that may have introduced new blocking or throttling settings.
Unable to allocate processing resources. Mistake: Authentication failed considering the remote party has closed the transport stream.
What This Means
- The fill-in job failed due to an hallmark error betwixt the client machine bankroll upwardly and the eSilo infrastructure.
Possible Causes
- Client machine is behind on Windows Updates which include authentication and security enhancements, or they have non checked the box in Windows Update Settings to include updates for other Microsoft Products, such as .NET Framework.
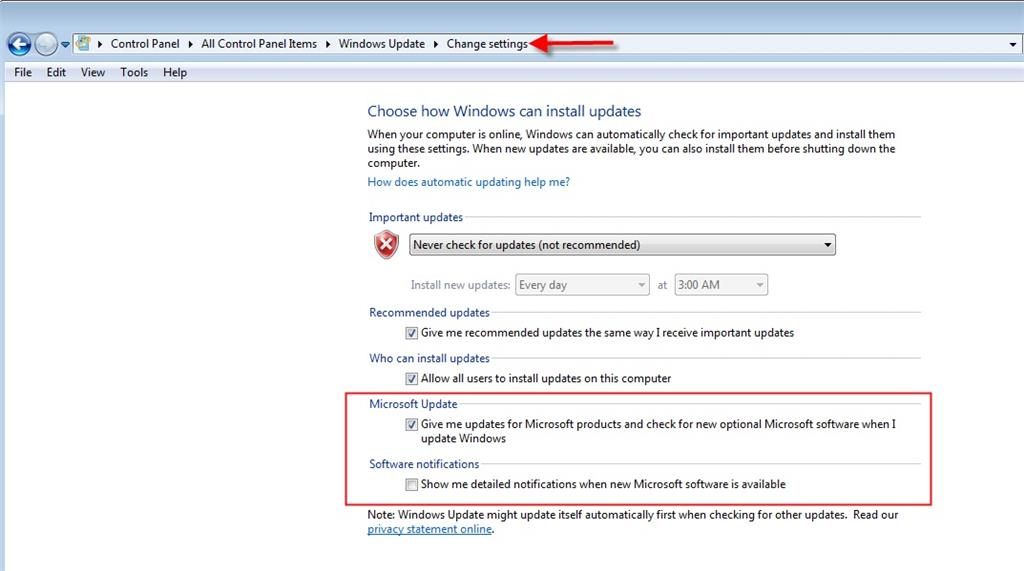
Troubleshooting Steps
- Apply latest Windows Security updates and .NET Framework updates
- Cheque if at the time of the in a higher place error on the tenant side, the eSilo Svc.VeeamCloudConnect.log log file displays the following error: "A call to SSPI failed, run into inner exception". If so, the upshot may be related to a Windows Update enforcing a new .Net Framework security bank check. This cheque does non allow the client to establish a secure connection between their Veeam backup servers or agents and the eSilo Cloud Connect service, if there is a weak Diffie-Hellman Imperceptible (DHE) cardinal. See this help commodity from Veeam on the steps needed to ostend and resolve. https://www.veeam.com/kb3208
- Subsequent job reattempts may consummate successfully without user intervention, although this error may still sporadically cause jobs to fail.
Error: Failed to connect to the port [DNS_Name:Port].
What This Means
- Host unable to connect to eSilo cloud connect at the specified gateway and port accost.
Possible Causes
- If this issue is occurring for only one or two machines (about mutual), and not all machines connecting to the eSilo cloud connect infrastructure, information technology may be indicative of a network issue on the client side.
Troubleshooting Steps
- The host should reattempt the job at the next scheduled interval. You tin can also manually start a backup to reattempt the job. No other user intervention is typically required.
Mistake: Insufficient quota to complete the requested service. Asynchronous read operation failed Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}. Exception from server: Insufficient quota to consummate the requested service. Asynchronous read operation failed Unable to retrieve side by side block manual command. Number of already processed blocks: [#]. Failed to download disk '[LONG_ID]'.
What This Means
- The mistake description may be misleading. Nosotros've observed this error previously, and it was unrelated to the Tenant's Quota, which was well within limits.
Possible Causes
- When this was observed on an internal testing VM, the cause was that the source VM in the backup task was very low on memory (RAM) resources and was unresponsive. Restarting the VM brought it back online, and the next automatic job effort was successful.
Troubleshooting Steps
- Verify the source machine is online and responsive. Ensure resource levels wait skilful.
- Host will reattempt task at the next scheduled interval. No user intervention is typically required.
Error: Invalid fill-in cache synchronization land.
What This Means
- Host is currently saving backups to Local Fill-in Cache. An attempt to sync cached backups to the eSilo cloud repository failed, due to a mismatch betwixt what the Veeam Agent for Windows had in its local database for expected restore points and what was actually establish in the repository and/or local backup cache.
Possible Causes
- If an in-progress backup is abruptly stopped, for example due to power failure, Veeam will discard whatsoever partially written restore points. Nonetheless, if all references to those now discarded restore points are non cleared from the database (which should happen automatically), this tin can cause a task error on the next run, which highlights a mismatch between restore points expected on disk and what was establish.
Troubleshooting Steps
- In most cases where this has been observed, the job will complete successfully the next time information technology is run, without any user intervention.
- If this error persists more one time, contact eSilo Support for aid troubleshooting Backup Enshroud problems.
Task session for "[JOB_NAME]" finished with error. Job [JOB_NAME] cannot be started. SessionId: [ID], Timeout: [Xx sec]
What This Means
- The Veeam chore could non offset due to likewise many active sessions or jobs running on the host consuming all available retentiveness.
Possible Causes
- Too many running sessions causes Veeam services to be impacted by the host'southward Desktop Heap limitation. This is because the Desktop Heap size for services is much smaller than that for applications.
Troubleshooting Steps
- To resolve this issue the Desktop Heap size must exist increased via a registry modification.
- See this Veeam Knowledge Base article for detailed resolution steps: KB1909
Error: The system cannot find the file specified. Failed to open I/O device Failed to open emulated deejay. Failed to open up deejay for read. Failed to upload deejay. Agent failed to procedure method {DataTransfer.SyncDisk}
What This Ways
- An expected disk on the client car (auto to backup) was unable to be opened and read during the backup job.
Possible Causes
- Not known at this time.
Troubleshooting Steps
- The host volition reattempt task at the next scheduled interval. No user intervention is typically required.
Error: Oib is complete and cannot exist continued
What This Means
- The "oib" stands for "objects in backup" and is a unique identifier used past Veeam.
- The fault indicates there is a discrepancy; a task is attempting to write to an oib that is already consummate or finalized.
Possible Causes
- This may occur on a backup cache sync job that was interrupted right at very end, during the finalization stage. The error indicates that the oib was finalized by the previous chore ("oib is complete"), however the current job is trying to modify or suspend to it, which is not immune.
Troubleshooting Steps
- This fault should resolve itself on adjacent chore run. If non, contact eSilo support.
Job session for "[JOB_NAME]" finished with error. Backup cache size has been exceeded
What This Means
- The size of the local backup cache has exceeded the maximum immune size every bit configured in the fill-in chore, preventing new restore points from being saved to the cache.
Possible Causes
- Persistent network disruptions may be preventing cached restore points from syncing, or uploading, to the eSilo Backup Deject and thus they are not rotated out of the local backup cache. Restore points accumulate until the backup enshroud location is full.
- Service provider resources are busy or unable to be allocated to this host, preventing the syncing of cached restore points.
Troubleshooting Steps
- The Fill-in Cache Sync should resume in time, once the originating network or resource problems are resolved.
- The maximum Fill-in Cache size can exist increased in the job settings, and so long every bit there is sufficient local space.
- For more item on advanced resolution steps, run into this eSilo KB article: How to Resolve Backup Cache Size Exceeded Mistake
Error: Failed to create snapshot: Backup job failed. Cannot create a shadow copy of the volumes containing writer's information. A VSS critical writer has failed. Author proper noun: [NAME]. Class ID: [ID]. Example ID: [ID]. Writer's state: [VSS_WS_FAILED_AT_PREPARE_SNAPSHOT]. Fault code: [0x800423f0].
What This Means
- There is an issue with the born Windows VSS (Volume Shadow Copy service) on the host machine. Specifically, the VSS writer mentioned was not available at the time of the fill-in.
- eSilo Backups powered by Veeam use VSS writers to fill-in files that may be in-employ, open up or locked at the time of fill-in. This is specially useful for databases, allowing backups to complete without reanimation. If a writer is non in the proper state and functioning every bit expected, the backup snapshot will fail. VSS writer issues must be resolved on the host, and tin can unremarkably be corrected by restarting the associated service.
Possible Causes
- The VSS service and/or the VSS Providers service is disabled
- The VSS author is non in the Stablestate, indicating it is fix and waiting to perform a backup. Below are culling states:
- Failedor Unstable – the Writer encountered a trouble, and must be reset .
- In-Progress or Waiting for Completion – the Author is currently in utilize past a fill-in procedure. When the backup is finished, the Writer will revert to dorsum toStable country. Withal, if you run across this country when no backups are running, the Writer needs to be reset.
Troubleshooting Options
- Verify the Volume Shadow Re-create and Microsoft Software Shadow Re-create Provider services are not disabled inservices.msc.
- Check the state of VSS Writers using the following syntax in an admin command prompt. Besides cheque the Windows Event Viewer for additional fault information.
vssadmin list writers
-
- For the specified Author in the mistake message, verify information technology is in a Stableland. If not, restart the respective Service related to that writer every bit mentioned in the tablehere. Then run the above control a second time to ensure the author has returned to a stable country.
- Note that Services often take dependencies on 1 some other. When 1 service is reset information technology may crave others to exist reset as well. Restarting a service will momentarily disrupt any application services that rely on information technology. For example, while resetting the MEIS service (Microsoft Substitution Information Store), MS Substitution volition exist unable to send and receive emails.
- A system reboot tin can also resolve well-nigh VSS writer problems, although it requires downtime.
- This Veeam KB commodity can as well exist useful in troubleshooting VSS bug for servers.
Job Session for [JOB_NAME] finished with fault. Job [JOB_NAME] cannot exist started. SessionID: [ID], Timeout: [VALUE]
What This Means:
- The task could not beginning, due to timeout waiting for required Veeam resource
Possible Causes:
- The Concurrent Task limit prepare at the Company level is too low for the number of hosts and disks schedule to be backup within a defined backup window.
Troubleshooting Options:
- Increment the number of concurrent tasks (east.1000. disks that can be candy at one time). This setting tin be plant in the eSilo Backup Portal under Companies >> Edit >> Bandwidth >> Max Concurrent Tasks. The minimum value should be 2, merely greater numbers may be needed based on the timing and staggering of host backups.
Job session for "[JOB_NAME]" finished with fault.
Error: Service provider side storage commander failed to perform an functioning: CreateStorage
What this Means:
- eSilo was not able to allocate repository storage for the backup job.
Possible Causes:
- The assigned repository quota for this Tenant has been exceeded, thus preventing new backups from initiating.
Troubleshooting Options:
- Increase the Company's repository quota.
- Remove existing backup bondage or reduce the memory period to free space.
Job Status Warning: Unable to truncate SQL server transaction logs. Details: Failed to truncate SQL server transaction logs for instances: [MSSQLSERVER].
What this Means:
- Veeam was unable to truncate SQL server logs as specified in the job settings.
Possible Causes:
- This most commonly due to a permissions effect.
Troubleshooting Options:
- This Veeam Helpcenter article discusses the Log Truncation settings.
- You tin confirm if this is a permissions outcome by reviewing the Fill-in Chore log for Warning items. Ex: Description = The server principal "[HOST]\[Business relationship]" is not able to access the database "[HOSTNAME]" under the current security context.
- Grant necessary permissions and rerun the job.
- Alternatively, y'all can modify the Backup Job settings to not truncate SQL Logs.
- Edit the Fill-in Task
- Under Invitee Processing, click to "Customize awarding handling options for individual applications…"
- On the SQL tab, select the selection for "Do non truncate logs"
2. Job Session Country Errors (for VMs)
Host [LOCAL_IP] is not available. Error: Cannot consummate login due to an incorrect user name or countersign. Virtual Car [NAME] is unavailable and will be skipped from processing. Nothing to process. [#] machines were excluded from job list.
What This Means
- Veeam Backup and Replication was unable to admission the Virtual Car (VM) to perform the backup.
Possible Causes
- Incorrect user proper name or password specified to access the source VM. The password may take expired or the account credentials or permissions may take been changed.
Troubleshooting Steps
- Contact the IT Administrator for the VM to troubleshoot the credentials saved in the Backup Task.
iii. Job Status Errors
SQL VSS Writer is missing: databases will be backed upwardly in crash-consistent land and transaction log processing will be skipped
What This Means
- The SQL Writer for the Windows Volume Shadow Copy Service (VSS) is not bachelor on the host machine, or is non configured with adequate permissions. This consequence is related to the setup of the SQL database, and non specific to eSilo provided software or the backup itself.
Steps to Ostend the Issue
- Running 'vssadmin list writers' in an Administrator Command Prompt shows that SqlServerWriter is not in the list, or is in a State other than 'Stable'.
Possible Causes
- The SQL example has at least one database with name starting or ending in a space character
- The account under which SQL VSS Author service is running doesn't have sysadmin role on a SQL server – nigh frequently encountered
- SQL VSS Writer service is stuck in an invalid land, e.grand. other than 'Stable'
Troubleshooting Steps
- Depending on a particular cause:
- Rename the database to a new name (without a space in information technology). To check if your database has space in the name you can run the post-obit query:
select name from sys.databases where name like '% '
If yous notice any spaces in the database names, and so y'all will need to remove the spaces from the database names.
- Grant the SQL VSS Writer service user a sysadmin role (Instructions in KB here: https://www.veeam.com/kb1978)
- Restart SQL VSS Author service (Instructions in KB here: https://www.veeam.com/kb2041)
- In the case of SBS machines that are also Domain Controllers, ensure that the SQL Writer is running every bit a domain administrator and not local organization.
- Allow the SQL Writer service business relationship access to the Volume Shadow Re-create service via the registry:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\VSS\VssAccessControl- If the DWORD value "NT SERVICE\SQLWriter" is nowadays in this key, it must exist set to i.
- If the Book Shadow Copy service is running, stop it after changing this registry value. Exercise not disable it.
For More Data
Run across this Veeam Knowledgebase article: https://www.veeam.com/kb2095
Microsoft documentation states that the SQL Author service must run equally Local System.
- In SQL Server 2008R2 and earlier, this means that the writer service business relationship appears to SQL Server as "NT AUTHORITY\Organisation".
- In SQL Server 2012 and later, the writer service account appears to SQL Server as "NT Service\SQLWriter".
4. Computer/VM Not Backed Up Errors
Backup Agent '[HOSTNAME]' has fallen out of the configured RPO interval ([#]days). Concluding fill-in: [#] days, [#] hours ago.
What This Ways
- The host's most contempo eSilo cloud backup is greater than the specified RPO (Recovery Point Objective) interval.
Possible Causes
- Host has been powered off or offline.
- Backups are being saved to the host'due south Local Backup Cache and all restore points in the enshroud have non notwithstanding synced to the eSilo Deject Repository (e.g. eSilo has not even so received the backups).
- Veeam Backup Agent Service or Veeam Direction Agent Service is not running on host.
- The backups and/or backup schedule have been manually disabled (uncommon).
Troubleshooting Steps
- Verify host is online and connected to network.
- Bank check Backup Chore to determine if Backup Enshroud is enabled. View cache folder on host to see if populated with recent restore points (default location: C:\VeeamCache).
- Verify 'VeeamManagementAgentSvc' service is running on host. Status should be 'Running' and Startup Type should be 'Automatic (Delayed Kickoff)'. If the service is 'Stopped', cheque the Event Viewer for possible mistake details. Come across this article for more than troubleshooting steps.
- Verify 'VeeamEndpointBackupSvc' service is running on host. Status should exist 'Running' and Startup Type should exist 'Automatic'. Restart or reinstall if necessary.
- Check Backup Job to verify schedule and ensure not 'Disabled'
Other Errors –Full Details Coming Shortly
Error: Reconnectable protocol device was airtight. Agent failed to procedure method {FileBackup.SyncDirs}. Exception from server: Reconnectable protocol device was closed.
Troubleshooting Steps
- Host will reattempt job at the next scheduled interval. No user intervention is typically required.
Error: A connection attempt failed considering the connected party did non properly reply after a flow of time, or established connection failed considering connected host has failed to respond.
Troubleshooting Steps
- Host will reattempt task at the next scheduled interval. No user intervention is typically required.
[In Backup Job Log] Error: [CStorageLinksHelper] Link Id=[LONG_ID] doesn't exist for storage [JOBNAME_SUBTENANTNAME]yyy-mm-ddTxxxxxx.vib
What This Means
- While the restore indicate exists on the repository, the Link ID to that restore signal in the metadata (.vbm) file is missing.
- Annotation: If the Backup Job is configured to use Backup Enshroud, this error does not by itself trigger a Backup Job Failure, since the restore points are successfully written to local cache. You will notice it however, because the eSilo Fill-in Portal volition warn that a new restore point has not been uploaded in X days (according to the RPO alarm thresholds set for this tenant).
Possible Causes
- This can exist a symptom of a network drop, where a handshake was missed in the final stages of job completion for the last restore point uploaded to eSilo. The local Veeam Agent database (on the subtenant's machine) saw the restore point created, but the finalization step didn't update the metadata file on the repository side with eSilo.
Troubleshooting Steps
- In the repository, we volition strength the job to recreate the metadata file by editing the existing metadata file to suspend ".old" at the cease. At the next job run, this volition force a recheck of all restore points in the backup chain and recreate the metadata file from that chain.
[In Svc.VeeamEndpointBackup.log] Error: Warning [CertificateError] Validation complete with warnings, AND/OR Warning Remote certificate chain errors, AND/OR Warning WarningRevocationStatusUnknown (The revocation function was unable to check revocation for the certificate.
What This Means
- The subtenant was unable to validate the eSilo Cloud Connect server's document.
Possible Causes
- If this is happening for only one tenant, every bit opposed to all tenants, information technology suggests an issue with how this specific subtenant is connecting to eSilo.
- If no firewall or other changes have been made recently, you can recheck the credentials used by the subtenant in the backup job.
- This Veeam KB article is likewise helpful for investigating common causes of certificate errors: https://world wide web.veeam.com/kb2323
Troubleshooting Steps
- Verify the Management Amanuensis status shows as Connected. You lot can forcefulness a reconnect past changing a holding in the dialog box, and so irresolute information technology back and clicking "Apply".
- Pause and unpause sync of Backup Cache files by correct-clicking on the Veeam Fill-in Agent icon in the taskbar.
- Edit the Fill-in Job to specify the right sub-tenant login credentials. Relieve and rerun the job. Upon the next chore run, you should see "Uploading cached restore points" when you lot hover over the Veeam Fill-in Amanuensis icon in the taskbar.
Was this commodity helpful?
Source: https://www.esilo.com/knowledge-base/troubleshooting-veeam-error-messages/
0 Response to "Upload Attempt Failed Time Out Reached for Upload Attempt"
Post a Comment